2020-03-20 10:17:53
來源:深信服科技
海量數據時代來臨,但在這上空飄著一朵烏云——那就是海量小文件的存儲問題。
海量小文件是怎么產生的?
海量小文件:業內通常將大小在1MB以內的文件稱為小文件,百萬級數量及以上稱為海量,由此量化定義海量小文件。
首先我們來看一下海量小文件是怎么產生的?
人工智能、物聯網、智慧金融、智能安防、傳感器網絡、科學實驗等應用的發展產生了大量數據,這些數據種類繁多,大小不一。不僅包括海量的大文件(大于1MB),也包括海量的小文件(小于1MB)。特別是小文件的數量將達到千萬級、億級甚至十億、百億級。
在智能安防領域有很多典型的海量小文件場景,人臉識別就是其中之一。人臉識別的基礎原理,就是通過將攝像機拍攝的圖片與視圖庫進行比較,如果匹配則命中。對于一個大型城市來說,攝像機抓拍的圖片數量會達到百億級規模。在對這些原始數據進行分析應用的過程中就會涉及到對百億級規模的海量小文件的處理。
類似的還有智慧金融,這也是一個會產生海量小文件的場景。金融業務不僅有大量原始票據通過掃描形成圖片和描述信息文件,還有電子合同、簽名數據、人臉識別數據等。金融的影像數據一般單個文件大小為幾KB至幾百KB不等,文件數量達到數億至數十億級規模,并且逐年增長,需要做長期的保存。
海量小文件,存儲大煩惱
海量小文件體量龐大,但目前的文件系統包括本地文件系統、分布式文件系統都是匹配大文件場景的。從細節來說,如對元數據的管理、數據布局、緩存管理等的實現策略都側重于大文件,導致在海量小文件情況下,存儲處理性能極差。(比如日常的文件拷貝,如果拷貝一個大文件的電影到移動硬盤,拷貝的速度能達到100MB/S,但是如果拷貝的是超過上萬個小圖片,拷貝速度可能不到5MB/s)
因此,海量小文件存儲問題一直被認為是工業界和學術界的難題,是海量數據時代上空飄著的那朵烏云。如前面所講的智能安防、智慧金融的存儲架構方案設計,就需要重點考慮到存儲系統對于海量小文件的處理性能難題。
具體來說,導致海量小文件處理性能差的原因主要有如下三點:
元數據管理低效的問題
講這個問題之前,我們先認識一下元數據。在存儲系統中,數據分為兩部分進行存儲:一部分是真實數據;另一部分是描述這份數據的元數據,比如文件系統中文件的文件名、文件大小、執行權限等。元數據有著明顯特點,那就是數量多,而且容量小。

在通用的文件系統設計中,如果需要訪問一份真實的數據就需要先訪問到該數據的元數據。可是我們知道,當前主流的文件系統基本都是面向大文件設計的,在海量小文件的情況下,因為必然會產生更大數量級的元數據,這會放大文件系統擴展性差、檢索效率低的問題。比如傳統NAS存儲采用二叉樹結構進行數據的存放,這種方法在遇到海量小文件的時候,文件系統在存儲海量小文件的同時還需要存儲更大數據級的海量元數據,NAS存儲在擴展性和檢索速度方面很容易就達到了瓶頸。所以,傳統的NAS文件系統在海量小文件下,性能衰減得異常厲害,一般文件數量級到達千萬級的時候效率就會變得極其低效。
因此,如果想要徹底解決海量小文件的問題,首先就需要存儲系統有一個健壯高效的元數據管理平臺(庫)。如果沒有核心技術解決這個問題,這個存儲系統即使在其他方面的優化做得再好,也僅能滿足幾個億級別的小文件存儲,而無法滿足百億級別的小文件存儲。
I/O訪問流程復雜的問題
傳統的文件系統在文件讀寫的時候流程過于復雜,在讀取一個文件的時候,需要產生多次I/O。例如對于Linux系統在讀取文件的時候,至少需要先讀取文件目錄元數據到內存,緊接著把文件的索引節點(inode)裝載到內存,最后再讀取實際的文件內容,在訪問數據過程中會多次讀取元數據,效率極低。
機械磁盤對于隨機小I/O讀寫性能低
當前很多文件系統都是將元數據分散存儲,從真實存儲的位置來看分散在存儲的所有磁盤當中,因此元數據的讀寫屬于隨機的I/O。然而機械磁盤對于隨機的I/O性能極低,因此在海量小文件的場景下由于元數據讀寫會產生隨機高頻次的I/O讀寫,對于當前以機械盤為主的存儲系統來說,性能極差。
(采用全閃存效果會比較好,但是目前來說,對于海量的非結構化數據若使用全閃存,從成本來看并不現實)
解決海量小文件存儲難題
需要對癥下藥
綜合上述分析,如果想要解決好海量小文件的存儲難題,就需要對癥下藥。對于海量小文件的存儲優化可以從元數據管理、數據組織、I/O 流程優化與緩存管理(業界通常稱為Cache管理)等幾個方面下手。具體的技術包括通過優化元數據管理與數據組織方式、小文件合并、優化緩存命中率等方面,來提升海量小文件的存儲性能支撐,從而達到提升海量小文件訪問效率的目的。
元數據的承載。正如上文所說,海量小文件處理的瓶頸在于對元數據的處理,業內通常采用分布式數據庫實現。通過對元數據進行獨立組織與承載,并通過元數據語義優化、寫入優化等,降低元數據在I/O路徑和資源等方面不必要的性能消耗與寫入次數。匹配上優化的技術,減少I/O數量,比如在處理業務高并發的時候,將并發的多個操作合并成一個操作,進一步提升吞吐。最后,為了進一步保障元數據的小I/O高性能,通常將元數據存儲在SSD的數據分層空間中,進一步加速元數據的訪問效率。
分布式智能緩存技術。針對海量小文件設計的分布式智能緩存層,能夠讓小文件在寫入SSD后即返回,縮短I/O路徑,有效降低時延,提高性能。同時還可以有效降低原生糾刪碼的I/O寫入放大的問題,提高原生糾刪碼的性能,進一步提升分布式存儲對海量小文件的性能支持。
小文件合并。通過將小文件落在智能緩存的同時還能夠將小文件在線合并成大I/O,然后通過條帶化技術(將大數據切分成小數據并發存儲到不同硬盤)寫入HDD,極大地提升了I/O的性能。并且小文件合并還能夠減少文件數量,從而減少對應的元數據數量,來提升性能。
行業難題與機遇往往相伴而行,各大廠商在攻克海量小文件存儲難題上各顯神通,既有老牌廠商,也有近年來異軍突起的新銳玩家。在這其中,深信服存儲宛若一個老道的新手,在海量小文件的處理上攜清晰的解題思路強勢入局。根據深信服公開的技術資料來看,其EDS對企業級分布式存儲處理海量小文件的性能優化思路與前面講的幾點不謀而合,其核心技術點可以歸納為三點:
第一,深信服推出了一個全新的分布式數據庫PhxKV來對獨立承載元數據。PhxKV具備優秀的性能擴展能力,能夠輕松承載數百億規模的元數據,成為深信服支撐百億海量小文件高性能的堅實基礎。深信服內部進行的性能測試顯示,PhxKV使用兩核時的吞吐,就能和MongoDB使用17核時的吞吐相當。
第二,通過智能緩存技術,采用高性能的SSD來加速海量小文件的讀寫效率并縮短I/O路徑。
第三,通過小文件合并技術來降低文件的數量,從而減少整體I/O讀寫頻次來提高I/O性能。
尤其是針對海量小文件的頑疾,深信服企業級分布式存儲EDS在性能提升方面表現搶眼,并且在權威機構測試和用戶的實際應用中得到檢驗。
日前,深信服企業級分布式存儲EDS通過中國泰爾實驗室權威機構多項指標測試驗證,其中對海量小文件承載的性能表現很搶眼。根據測試數據,深信服EDS通過三節點構建的對象存儲能夠輕松承載100億小文件,且性能抖動不超過5%;對象上傳速度達到15,000個/s,對象下載速度達到40,000個/s。
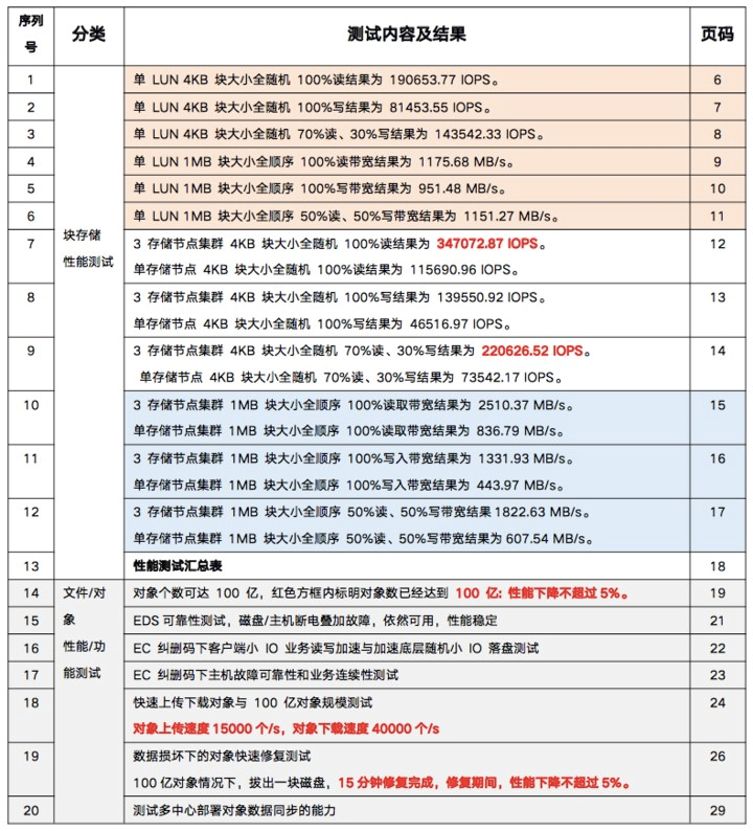
▲深信服EDS中國泰爾實驗室測試內容及結果
值得一提的是,深信服EDS在處理海量小文件時呈現出的高性能,是通過軟件機制和優化來充分發揮硬件長處、激發硬件潛能,最終實現用更低成本的硬件平臺,也能夠獲得高性能,帶來的是更具性價比的解題思路。
海量小文件實踐案例
南方某市公安系統采用了深信服分布式存儲進行智能安防的數據存儲,其中涉及到3.5PB的視頻存儲以及數十億級別的人臉識別的海量小文件存儲,是一個典型的大文件與海量小文件混合存儲的場景。
深信服企業級分布式存儲EDS采用對象存儲與平臺進行對接,系統峰值每秒有將近3,000張圖片寫入存儲系統。目前存儲系統內保存的海量小文件數量已經超過50億,而且還在不斷增長當中。得益于深信服在海量小文件的性能優化,使得EDS平臺能夠從容應對大并發的人臉識別系統,并且滿足后續針對原始圖片數據的二次挖掘應用。
對于非結構化數據存儲來說,攻克了海量小文件存儲難題,基本代表了該存儲能夠適配絕大多數非結構化數據存儲的場景。深信服分布式存儲基于軟件定義技術、采用通用的X86服務器與以太網交換機,激發硬件潛能,在海量數據時代幫助用戶構建一個可靠、高性能、智能管理的海量數據存儲平臺。
關于深信服新IT
深信服基于軟件定義重塑IT基礎架構,為用戶提供敏捷、智能、安全的新一代IT基礎設施,包括桌面云aDesk、應用交付AD、軟件定義廣域網SD-WAN、企業級分布式存儲EDS等。深信服打造的新一代IT基礎設施解決了傳統基礎設施面臨的效率低、成本高、安全性差等一系列問題,加速用戶的數字化轉型進程。