
2020-05-22 15:53:44
來源:深信服科技
這類業務,并不需要文件系統提供的復雜語義。相反,只需要存取(PUT / GET)的簡單操作模式,使得這類業務非常適合使用對象存儲。雖然對象存儲相比文件存儲更擅長處理數目巨大的非結構化數據,但對于十億甚至百億的規模,依然會對現有的系統(如軟件定義存儲中最常用的 Ceph)造成嚴重的性能和可用性的沖擊。本文將介紹如何通過引入 adCache、PhxKV 等自研組件,成功支持百億級別的海量小對象存儲。
基于 Ceph 方案處理海量小對象的問題
為了說明 Ceph 處理小對象合并的問題,我們首先簡要回顧 RADOS Gateway ( RGW, Ceph 的對象存儲接口)的工作原理。RGW 工作在 Ceph 的底層存儲 RADOS 之上。RADOS 對外提供存取 RADOS Object (為了區分對象存儲,把 RADOS Object 稱為 R-obj )的接口。一個 R-obj 除去數據之外,還可以維護一定數量的 KV 形式表示的元數據( omap )。RGW 就是利用 RADOS 的接口,構建了對象存儲。其中,一個對象,會有三類與之相關的 R-obj。
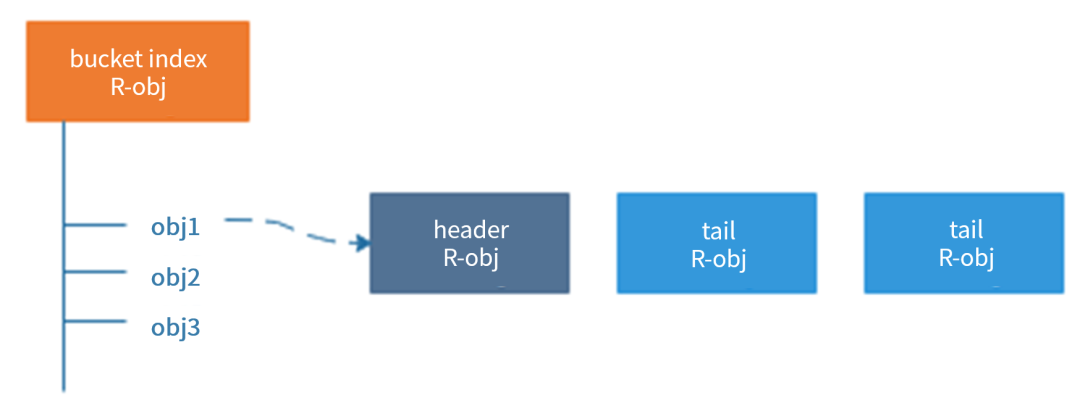
如上圖所示,對象存儲中的每個桶,都會有一個對應的 bucket index R-obj,桶中的每一個對象,都會對應該 R-obj
Ceph 底層存儲 RADOS 的一致性協議,為其處理海量小對象帶來了很大的問題。RADOS 在維護復制組 ( PG , Placement Group )的一致性時,要求復制組內所有在線(狀態為 up )的 OSD 都返回成功,一個 op 才算完成。而 OSD 的狀態,是由 monitor 監控 OSD 超時,更新視圖并擴散至全集群的。
在上圖的例子中,OP2 在處理過程中,從 OSD2 發生離線故障,這時,由于從 OSD2 仍然被認為在線,導致 OP2 被掛起,直到 monitor 更新從 OSD2 的狀態,OP2 才可以被返回。當 OSD2 從離線狀態重新上線時,會執行修復操作,同步自己和主 OSD 的狀態。
為了修復復制組中離線的 OSD ,重新上線的 OSD 會比對自身和主 OSD 中的 op log ,定位出離線期間發生修改的 R-obj ,并從主 OSD 中復制這些 R-obj 的副本。注意,RADOS 中 op log 的作用只為定位發生改變的 R-obj ,并不能通過 replay op log 的方式進行數據恢復。所以,發生變化的 R-obj 都需要進行全量修復。即使 bucket index R-obj 只是在從 OSD2 離線時插入了一條 omap,修復 bucket index R-obj 的過程中,依然需要復制整個 bucket index R-obj 的 omap 列表,且修復過程也會阻塞業務 I/O。
講到此處,已經不難看出 RGW 處理海量小對象時,元數據處理帶來的問題:
使用 PhxKV 承載海量小對象
我們已經說明了 RADOS 的一致性協議和修復機制在海量小對象場景中帶來的問題,接下來,將說明深信服企業級分布式存儲 EDS 是如何通過自研的分布式 KV —— PhxKV 來支撐海量小對象的元數據存儲。我們首先介紹區分于 RADOS 一致性協議的 RAFT 協議,之后介紹我們如何以 RAFT 協議為基礎,構建了 PhxKV 分布式 KV 系統。
RAFT 一致性協議
RAFT 協議有三個重要組成部分:Log,狀態機,和一致性模塊。一個 RAFT 組中有多個 peer,其中一個為 leader,其他為 followers。
如上圖所示,客戶端將 op 發送至 leader 的一致性模塊,之后 leader 請求所有的 peer 將該 op append 至 Log 中,當大部分(例如,三個 peer 中的兩個)append 成功時,就可以認為 op 已經 commit,這時,leader 更新狀態機,并返回請求。至于 followers , leader 會在后續的 op 中指示其將已經 commit 的 op log 執行,更新狀態機。
當 leader 發生故障,或者 leader 所在分片中的 peer 數少于大部分 peer 數導致 leader下臺時,RAFT 協議通過各 peer 間心跳的超時來觸發選主流程,從而進行視圖的變更。
RAFT 協議的具體細節和故障處理方面比較復雜,就不在此贅述,有興趣的讀者可以移步去閱讀論文 In Search of an Understandable Consensus Algorithm 。我們在此歸納 RAFT 協議的以下特點:
PhxKV 架構
接下來,我們介紹如何基于 RAFT 協議構建 PhxKV 系統。
PhxKV 的架構如上圖所示,PhxKV 提供和本地 KV 引擎類似的增刪改查和批量操作的同步異步接口。PhxKV 的 key 空間被一致性哈希映射到若干個 region 中,各 region 管理的 key 沒有重合,每個 region 對應一個 RAFT 復制組,通過 RAFT 協議維護一致性。PhxKV 采用 RocksDB 作為底層引擎,提供本地的 KV 接口。
PhxKV 的主要組件和角色如下所述:
PhxKV 針對業務特征,還進行了一系列深度優化:
PhxKV 在 EDS 海量小對象中的角色
除去 RADOS 一致性和修復帶來的問題,元數據規模過大,底層數據的碎片化也是 RGW 面對小對象合并時的棘手問題。EDS 使用另一組件,分布式緩存(adCache)和 PhxKV 雙劍合璧,一起打造了海量小對象的解決方案。AdCache 將數據暫時緩存在 SSD 盤上,后續再批量回刷至 RADOS,大幅降低了寫請求的訪問時延。
上圖表示了小對象合并架構中的各組件關系。在 Ceph 的原始實現中,RGW 將對象的數據和元數據都直接存儲在 RADOS 中,其中元數據以鍵值的形式存儲在 R-obj 的 omap 中。RGW 使用 librados 和 RADOS 進行交互。
為了實現上述改造邏輯,我們劫持了 RGW 對數據部分和元數據部分的操作。其中,元數據部分被重定向至 PhxKV 中。此外,數據操作被重定向至 adCache,adCache 用異步合并回刷的原則,后續對存儲的小對象被進一步聚合后,回刷至底層引擎 RADOS 中。同時,adCache 會生成二級索引,使得可以定位到小對象在合并后存儲的位置和偏移,在數據回刷至 RADOS 時,二級索引也會作為元數據被批量寫入到 PhxKV 中。
在采用了上述針對性的優化后,EDS 的小對象寫入性能,相比原生系統有了數量級的飛躍。小對象合并引入的二級索引雖然增加了讀取時的訪問路徑,但是由于減少了元數據的規模,也變相提升了 RADOS 的訪問性能,因此,整體的讀取性能并沒有下降。由于 RAFT 協議更健壯的修復機制,修復時間相比原生系統有成數量級的下降,而且能夠保持業務不中斷,修復過程中幾乎不出現業務性能的下降。
結論
海量小對象場景,是對象存儲的新機會,也為現有架構提出了新的挑戰。深信服 EDS 基于現有的架構,取長補短,合理引用新組件解決關鍵核心問題,并能夠讓老組件 RADOS 繼續發揮特長,為海量小對象的存儲打開了新思路。
作者介紹:
Eddison,從事分布式 KV 數據庫 PhxKV 的研發工作。香港中文大學博士,研究大數據存儲系統的性能和可靠性,在 USENIX FAST, USENIX ATC 等頂級會議發表多篇學術論文。從業以來,專注分布式一致性, KV 引擎,糾刪碼等領域,2018 年加入深信服科技。
備注:本篇文章首發于InfoQ,文章版權歸極客邦科技 InfoQ 所有。
關于深信服新IT
深信服基于軟件定義重塑IT基礎架構,為用戶提供敏捷、智能、安全的新一代IT基礎設施,包括桌面云aDesk、應用交付AD、軟件定義廣域網SD-WAN、企業級分布式存儲EDS等。深信服打造的新一代IT基礎設施解決了傳統基礎設施面臨的效率低、成本高、安全性差等一系列問題,加速用戶的數字化轉型進程。















