2020-07-16 14:12:03
來源:深信服科技
市場增長的主要驅(qū)動力源于當(dāng)前日益復(fù)雜的網(wǎng)絡(luò)安全形勢,網(wǎng)絡(luò)犯罪和黑客攻擊的規(guī)模和頻率不斷增加,且黑客不斷試水新技術(shù)來進(jìn)行攻擊,未知威脅頻發(fā)。安全團(tuán)隊(duì)對于未知威脅的抵御越來越捉襟見肘,行業(yè)開始尋求更先進(jìn)的解決方案來抵御未知威脅。深信服認(rèn)為,為達(dá)成上述效果,在未知威脅檢測方面,AI技術(shù)具有不可替代的優(yōu)勢。
為什么利用AI能夠檢測未知威脅?
泛化能力越強(qiáng),檢測未知威脅的能力就越強(qiáng), 檢出率就越高。
隨著新型病毒的大量出現(xiàn)以及網(wǎng)絡(luò)攻擊的愈加頻繁,現(xiàn)在業(yè)界普遍使用的基于規(guī)則或特征碼的檢測方案的有效性正在變得越來越低。一方面,黑白名單和傳統(tǒng)特征規(guī)則只能處理已知的惡意軟件,而對于未知攻擊,這類檢測方案的效用通常很低。另一方面,攻擊者的技術(shù)升級,新型惡意軟件越來越多,安全專家通過人工分析惡意樣本以提取新規(guī)則或特征碼的難度大大增加。
而基于人工智能的惡意文件查殺引擎優(yōu)于傳統(tǒng)基于特征碼的查殺引擎,原因在于機(jī)器學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)等AI技術(shù)具有泛化能力,通過使用已知樣本進(jìn)行訓(xùn)練就可以在未知樣本集達(dá)到很好的效果,因此可以發(fā)現(xiàn)新型的惡意文件。
以黑樣本為例,在攻擊手段迭代更新的過程中,黑客并不總是另起爐灶來重新制作攻擊向量。他們常常是通過對現(xiàn)有攻擊手段進(jìn)行優(yōu)化、整合和更新,進(jìn)而實(shí)施下一次攻擊。因此,未知威脅和已知威脅通常具有某種意義上的相似性。而AI檢測算法就是期望通過對已知數(shù)據(jù)的學(xué)習(xí),提取其中的固定模式,最終達(dá)到檢測相似未知的目的。相似的,白樣本的演進(jìn)流程中同樣存在這樣的比變量,比如開發(fā)代碼復(fù)用等。綜上所述,安全檢測場景中的泛化能力其本質(zhì)是檢測算法是否能夠提取潛在的固定模式,進(jìn)而在相似樣本集上輸出一致的檢測結(jié)果。
那么,如何評估檢測算法的泛化能力呢?
基于前面對泛化能力的分析,深信服安全專家給出了檢測算法泛化能力的一個評估方法:檢測算法的泛化能力等同其對相似樣本檢測結(jié)果的一致性。
簡單來說,可以通過以下兩步來衡量一個檢測算法的泛化能力:
1. 定義樣本相似性,用來描述你的泛化需求。比如指定相差10條指令的惡意文件為相似文件,那么你所關(guān)注的就是在已知樣本和未知樣本擁有10條指令差異下的泛化檢測能力。
2. 統(tǒng)計(jì)檢測算法在這些相似樣本上的結(jié)果一致性。一致性是表示檢測算法輸出的統(tǒng)一程度,具有強(qiáng)泛化能力的檢測算法應(yīng)當(dāng)在相似樣本上輸出相同的檢測結(jié)果。因此,一致性越高,則說明算法的泛化能力越強(qiáng);反之,泛化能力越弱。
泛化能力的量化評估公式具體如下:
1. 隨機(jī)選取N個樣本集,每個集合內(nèi)的樣本相互間具有相似性,標(biāo)記為S1,S2,...,SN。
2. 對每一個集合Si, 評估檢測算法的結(jié)果一致性。假設(shè)Si 有M 個樣本,將算法的檢測結(jié)果序列記為o1,o2,...,oM,計(jì)算o1,o2,...,oM表征的熵,記為ei。假設(shè)此檢測任務(wù)的理論最大熵值為E,則可以使用E-ei表征算法對Si的結(jié)果一致性。
3. C= E- (e1 + e2 + ... + eN)/N 則表征了算法在整個樣本集上的平均一致性, 即泛化能力。
業(yè)界引擎的泛化能力分布
目前很多安全產(chǎn)品中都集成了惡意文件檢測能力,在Virustotal平臺上就有70多家的惡意文件檢測引擎。從公開信息上看,不少檢測引擎都標(biāo)稱采用了機(jī)器學(xué)習(xí)算法。那么現(xiàn)在業(yè)界檢測引擎的泛化能力到底如何,AI檢測引擎之間是否有差異?
我們構(gòu)建了包含15萬黑樣本的共7256個相似樣本集。這些樣本覆蓋了2019.1.1~2020.5.20期間的線上熱門樣本。此外,通過VT平臺獲取70+業(yè)界引擎對相似樣本集的檢測結(jié)果(手動觸發(fā)重分析,確保為引擎最新結(jié)果),以公平比較他們的泛化能力。如下圖所示。圖中的每一個點(diǎn)對應(yīng)VT上一種檢測引擎,其中藍(lán)色的點(diǎn)表示深信服SAVE引擎的AI模型在不同配置下的效果;黃色實(shí)心點(diǎn)表示可從公開信息確認(rèn)的業(yè)界機(jī)器學(xué)習(xí)引擎;灰色的點(diǎn)表示技術(shù)路線未知的其他引擎。
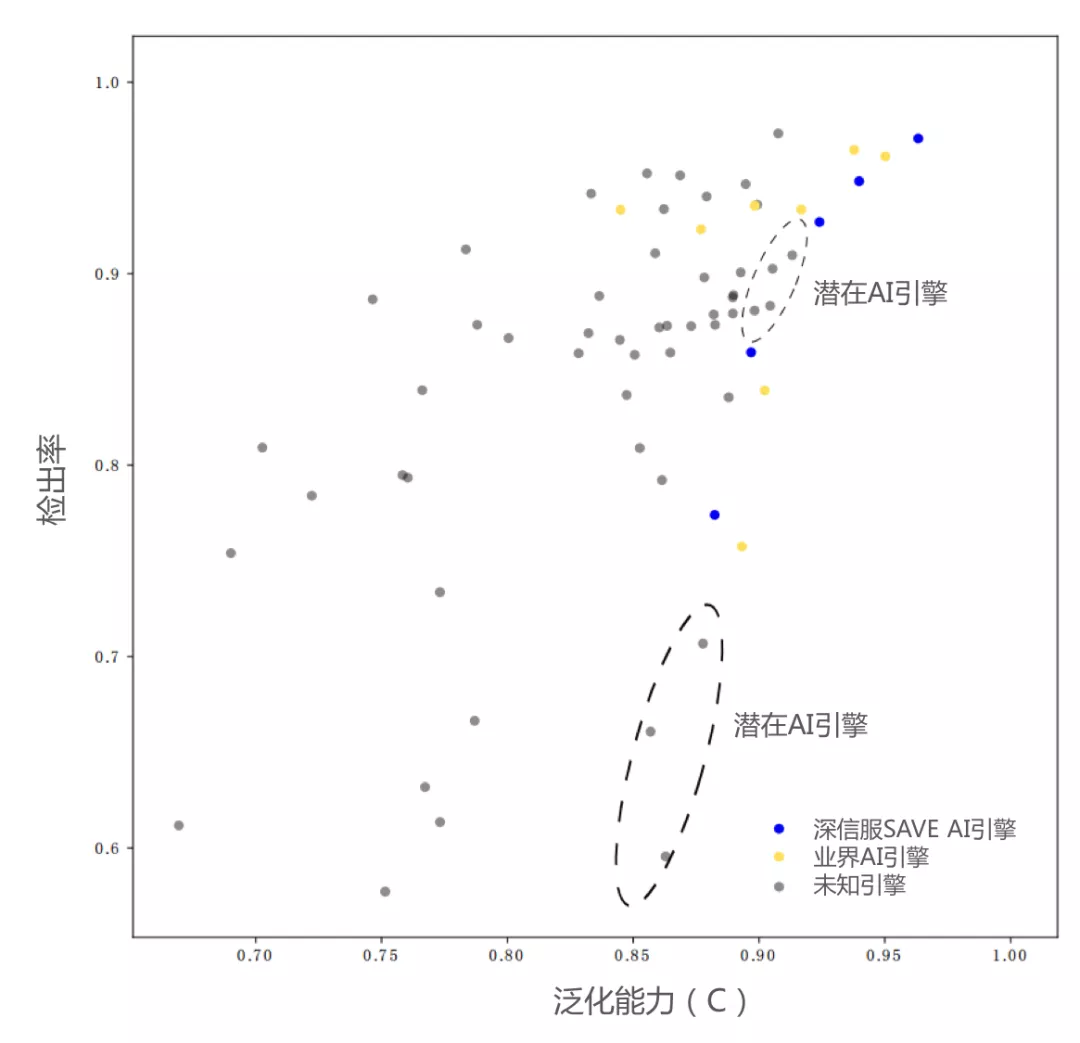
▲業(yè)界引擎的泛化能力分布