一、全球AI格局震動:中國團隊用1/10成本實現GPT-4級突破
近日,DeepSeek推出的開源模型引發(fā)了全球轟動,成為新聞頭條。當全球陷入“算力軍備競賽”時,成立僅一年多的中國AI企業(yè)DeepSeek投下“技術核彈”——以1/10的成本訓練的DeepSeek-V3實現了GPT-4o級別的能力,全新的推理模型DeepSeek-R1則實現了與OpenAI-o1相媲美的能力。這不僅是算法技術的突破,更是對“算力霸權”的一場漂亮反擊。
自美國實施芯片制裁以來,國內算力持續(xù)處于緊張狀態(tài),尤其是在國防領域,大模型私有化部署面臨的算力瓶頸已成為其實際應用的關鍵制約因素。在全球芯片封鎖的至暗時刻,DeepSeek用算法創(chuàng)新打破桎梏,用混合專家架構(MoE)結合強化學習技術,讓智能涌現突破算力的局限,為國防智能系統(tǒng)在芯片封鎖下的突圍提供了關鍵范式。
自成立以來,行至智能也始終致力于破解國防領域算力受限的困境,積極推動算法與工程協(xié)同創(chuàng)新,突破傳統(tǒng)依賴算力堆砌的局限,打造自主可控的大模型部署解決方案,實現了國防領域大模型高效落地的范式升級。如今在DeepSeek的加持下,行至智能已率先完成了DeepSeek的全國產化適配,能夠迅速為軍工用戶提供私有化部署與應用測試,推動國防智能化建設邁向新的臺階。
二、算法突圍:行至智能構建自主可控國防智能新范式
我們深信,針對大模型私有化部署的復雜場景,算法層和工程層的優(yōu)化,比單純依賴提升算力更為高效。尤其在面對“算力不足、標注數據稀缺和高專業(yè)性要求”的挑戰(zhàn)時,行至智能通過一系列前沿技術的突破,提供了創(chuàng)新性解決方案,推動國防智能化向更高效、更可持續(xù)的方向發(fā)展。
國產化環(huán)境下的模型混合精度訓練策略優(yōu)化
在模型訓練層面,行至智能采用了模型混合精度訓練策略,通過合理選擇不同精度的計算方式,優(yōu)化訓練過程。這樣既能降低算力消耗,又能確保模型的高性能。這一策略在國產化芯片環(huán)境下尤為重要,行至智能通過這一優(yōu)化措施成功克服了算力瓶頸,使得大規(guī)模模型能夠在國產化硬件上高效訓練,并保持較高的訓練質量,不僅提升了訓練效率,也為國防領域提供了具有可擴展性和可操作性的解決方案。
模型壓縮與輕量化部署:邊端場景的算力突圍
在模型部署層面,行至智能通過模型量化技術成功壓縮了模型計算精度,顯著降低了存儲需求和計算消耗,使得模型能夠在低算力環(huán)境下高效運行。同時,結合模型蒸餾技術,行至智能將大模型的知識轉移到小型化的學生模型上,從而減少了推理過程中的計算消耗,并保持了模型推理時的高精度和高效能,為邊端小算力設備的應用提供了技術保障。

投機采樣與推理加速:實時決策的技術保障
在模型推理層面,行至智能引入了投機采樣技術,顯著提升了大模型的推理效率。投機采樣通過在推理過程中預估最可能的輸出,減少了不必要的計算量,從而提高了推理速度和準確性。這項技術特別適用于需要實時決策和快速響應的場景,如軍事戰(zhàn)術推演和應急決策系統(tǒng),有力推動了大模型在國防領域快速決策的應用。
軟硬協(xié)同的推理框架深度優(yōu)化
為了充分適應國產化設備的特定需求,行至智能對推理框架進行了深度優(yōu)化。推理調度技術能夠根據設備性能和負載情況,動態(tài)調整任務的執(zhí)行順序,確保推理過程的高效性與穩(wěn)定性。而算子融合技術則通過將多個計算操作合并為單一操作,減少了數據傳輸和計算步驟,進一步降低了算力消耗。
強化學習驅動的作戰(zhàn)仿真系統(tǒng)革新
在軍事應用領域,行至智能構建了結合強化學習的大模型作戰(zhàn)仿真推演系統(tǒng),為國防領域的戰(zhàn)術推演和作戰(zhàn)模擬提供了前沿的解決方案。通過強化學習,系統(tǒng)能夠自主調整推演策略,以模擬復雜戰(zhàn)場環(huán)境下的決策過程,為指揮員提供更準確、更靈活的戰(zhàn)術指導,實現了高效的作戰(zhàn)仿真與實時決策。
三、顛覆性戰(zhàn)力躍升:基于DeepSeek掀起智能指揮系統(tǒng)效能革命
傳統(tǒng)AI訓練如同"紙上談兵",而DeepSeek開創(chuàng)了"戰(zhàn)場化演練"新范式。憑借DeepSeek的創(chuàng)新架構與算法,行至智能將為軍工領域帶來智能指揮系統(tǒng)效能的全面升級,為國防智能化建設提供強大而可靠的技術支撐。
模型架構創(chuàng)新: 作戰(zhàn)級智能體核心引擎
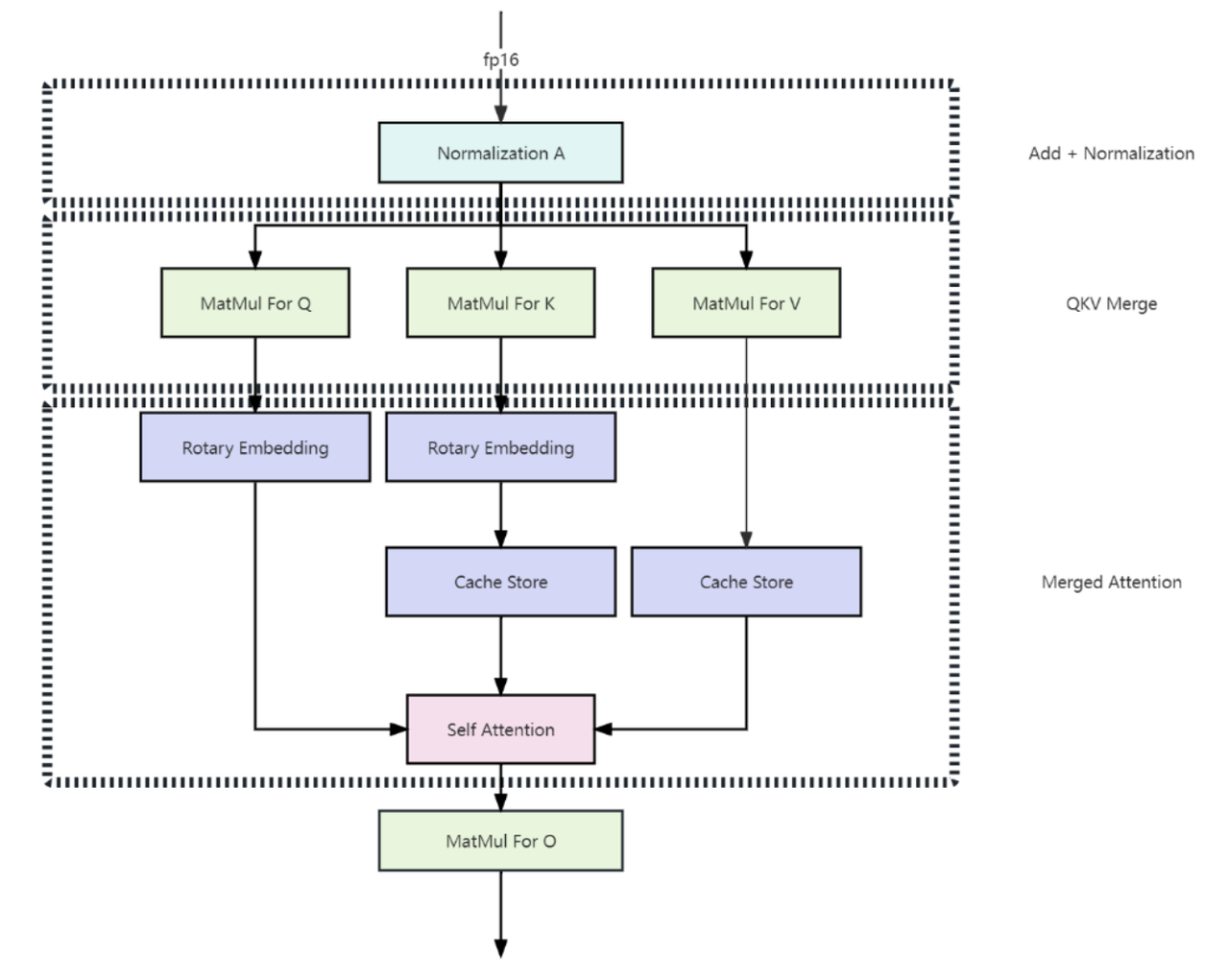
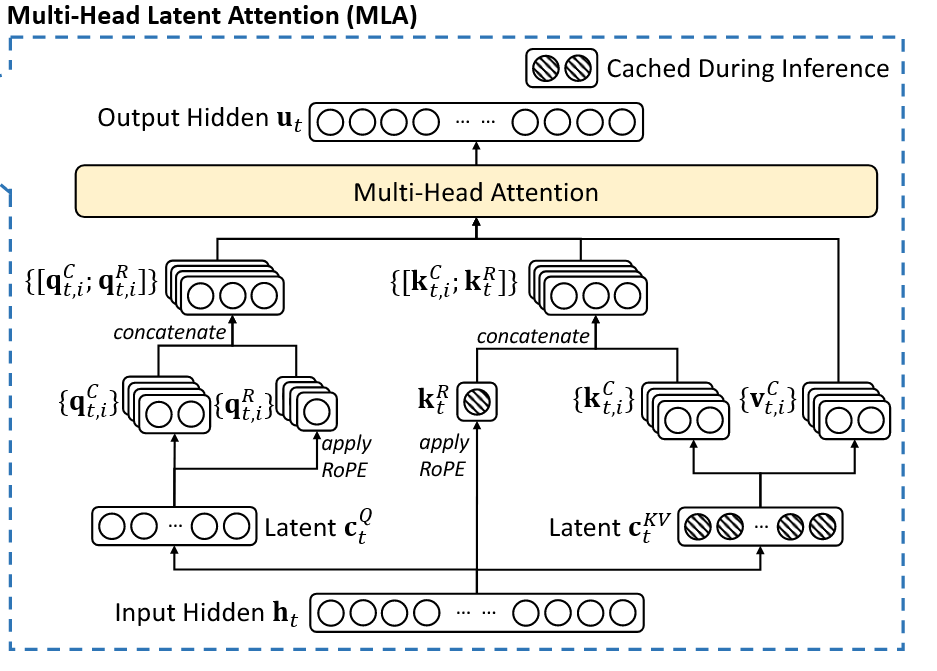
1. 多頭潛在注意機制(MLA):全域態(tài)勢感知加速器
針對傳統(tǒng)Transformer架構在戰(zhàn)場實時決策中的顯存瓶頸,多頭潛在注意力機制(MLA)通過低秩鍵值聯合壓縮技術將KV緩存銳減至傳統(tǒng)架構的1/8。搭載MLA的智能指揮系統(tǒng)可在同等硬件條件下,同時處理多戰(zhàn)區(qū)的實時態(tài)勢數據,相比傳統(tǒng)架構響應速度大幅提升,為多域聯合作戰(zhàn)提供毫秒級決策支持。
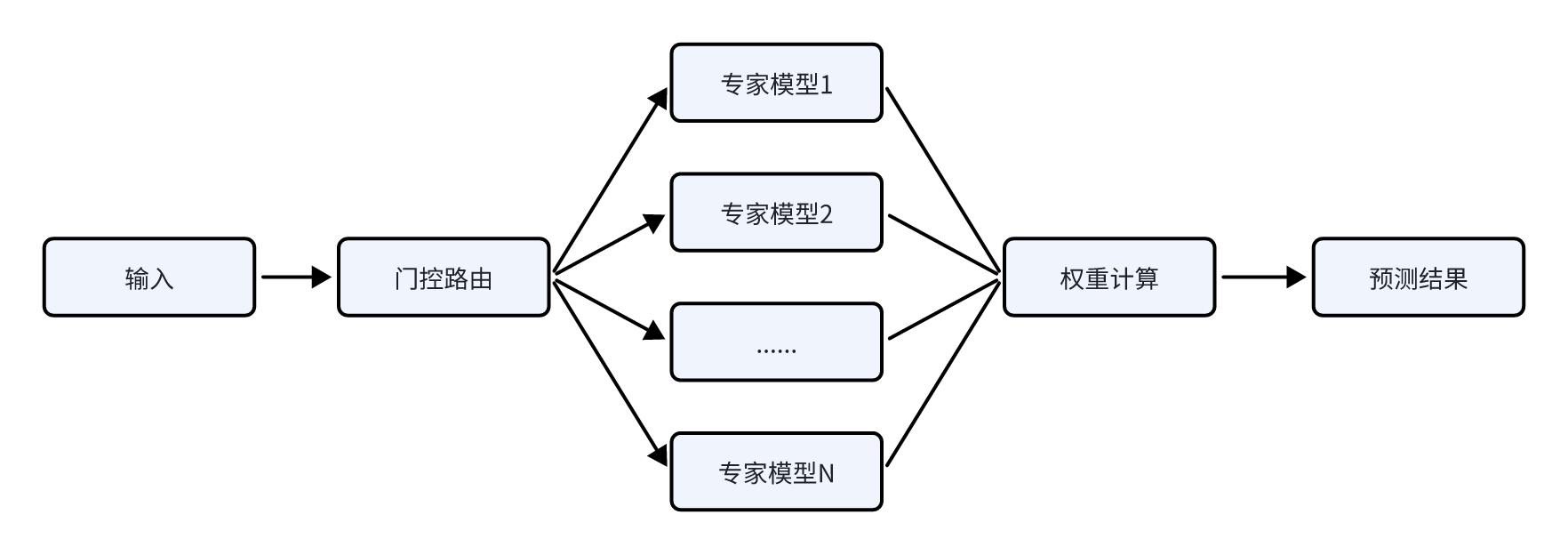
2. 混合專家模型(MoE):軍事專家網絡集群
混合專家模型(Mixture of Experts,簡稱MoE),其通過將模型分解為多個不同的專家模塊從而將單一任務空間劃分為多個子任務空間,從而讓模型精準地處理輸入,提升模型性能。
在國防場景中,可基于DeepSeek-MoE架構構建由256個專業(yè)模塊組成的軍事認知網絡集群,每個專家模塊深度專精特定作戰(zhàn)領域,例如:電子戰(zhàn)專家(具備復雜電磁環(huán)境下的信號特征提取能力),戰(zhàn)術規(guī)劃專家(融合經典戰(zhàn)役理論與現代復雜系統(tǒng)理論),威脅評估專家(集成多源情報的實時融合與威脅等級判定)等。在典型戰(zhàn)術邊緣計算節(jié)點(如某型智能巡飛彈)應用中,系統(tǒng)通過動態(tài)路由算法僅激活3-5個核心專家模塊,在保持37B參數有效計算量的同時,實現戰(zhàn)場環(huán)境識別準確率大幅提升,戰(zhàn)術決策時間相比傳統(tǒng)模型大幅壓縮。
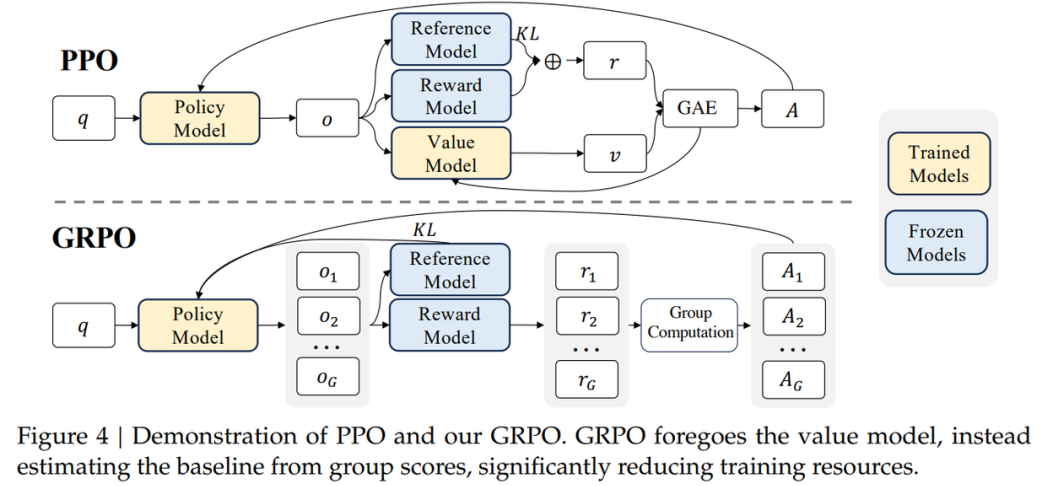
強化博弈推演:GRPO算法驅動的OODA環(huán)優(yōu)化
在DeepSeek-R1的強化學習階段,GRPO(Group Relative Policy Optimization)算法發(fā)揮了巨大的作用。GRPO算法相比傳統(tǒng)PPO強化學習效率大幅提升,尤其適合訓練參數量巨大的LLM和軍事對抗博弈場景。
在國防場景中,基于GRPO技術,可將結果驗證轉化為決策鏈監(jiān)控,構建透明可追溯的指揮系統(tǒng)。通過動態(tài)獎勵機制融合環(huán)境反饋與專家偏好,實現從單兵戰(zhàn)術到戰(zhàn)役推演的閉環(huán)優(yōu)化,有效提升決策過程的精準性和響應速度。
動態(tài)知識蒸餾:讓萬億參數戰(zhàn)力注入邊端設備
模型蒸餾是一種高效的模型壓縮與加速技術。在實際應用中,大模型通常在綜合數據集上進行訓練,具備較強的性能指標和優(yōu)異的泛化能力。然而,由于其龐大的尺寸和復雜性,這些模型往往無法在計算資源受限的設備上部署。通過知識遷移,蒸餾技術使得小型模型能夠實現更高的性能表現,從而在資源有限的環(huán)境中保持模型的可用性。
在國防私有化環(huán)境下,基于DeepSeek的大模型進行蒸餾,可以訓練出一系列針對特定任務的小型軍事專家模型。這些模型能夠在算力受限的設備(如邊端設備、便攜設備等)上高效運行,并且能夠達到專家級模型的效果。
突破算力瓶頸,推動國防智能落地
DeepSeek通過算法創(chuàng)新,打破了西方主導的"算力軍備競賽"邏輯,為國防智能系統(tǒng)在芯片封鎖下的突破提供了關鍵范式。作為國防領域大模型私有化技術的深耕者,行至智能也將繼續(xù)堅持技術創(chuàng)新驅動的戰(zhàn)略,致力于解決國防場景下算力受限、數據稀缺以及高專業(yè)性要求等問題,推動大模型在國防領域的廣泛應用,為國防智能系統(tǒng)的建設提供強有力的技術支持,并為未來智能化國防的發(fā)展奠定堅實的基礎。
附錄:技術創(chuàng)新概述
1. 多頭潛在注意機制(Multi-head Latent Attention)
在傳統(tǒng)Transformer模型中通常采用多頭注意力(Multi-Head Attention,簡稱MHA)作為注意機制的主要實現策略,但在模型生成過程中,其緩存(KV Cache)帶來了沉重的內存開銷并嚴重限制模型的推理效率。為了減少KV Cache,DeepSeek設計了一種名為多頭潛在注意力機制(Multi-head Latent Attention,簡稱MLA)的創(chuàng)新注意力機制,其通過使用低秩KV聯合壓縮方法(Low-Rank Key-Value Joint Compression),在性能優(yōu)于多頭注意力的同時顯著地壓縮了模型的緩存開銷,從而實現了模型訓練和推理效率的飛躍。
2. 混合專家模型(Mixture of Experts)
傳統(tǒng)AI大模型如同“全科醫(yī)生”,在處理任何問題時均需要激活全部模型參數來進行前向計算從而導致大量的運算開銷并帶來海量的顯存占用(KV-Cache)。而DeepSeek系列模型采用的混合專家架構——它將模型拆分為256個“專家模塊”,每個模塊專精特定領域,根據用戶輸入的指令,動態(tài)分配到合適的專模塊進行處理。在模型的訓練過程中,通過引入專家并行策略(Expert Parallelism)有效地減少了不同設備之間的通信開銷,從而顯著提升了模型的訓練和推理效率。以DeepSeek-R1為例,其具備6710億參數,但通過稀疏激活機制,R1每次推理僅激活5%的專家模塊(約37B參數),算力消耗降低90%。
3. 強化學習(Reinforcement Learning)
傳統(tǒng)觀點認為,要讓大語言模型 (LLM) 具備強大的推理能力,監(jiān)督微調 (SFT) 是必不可少的預備步驟。 就像給學生上課,先要用大量的標注數據“喂飽”模型,讓它學習推理的 “套路”。然而,DeepSeek-R1-Zero 卻打破了這個“定律”。它在DeepSeek-V3-Base的基礎上直接應用GRPO進行純強化學習 (Pure RL) 訓練,并在訓練過程中觀察到模型的持續(xù)性能提升和自我進化(自我驗證、反思以及生成長思維鏈等能力)。DeepSeek-R1-Zero的提出,首次公開研究證實:通過純強化學習(RL)可以激勵大型語言模型(LLMs)的推理能力。
在DeepSeek-R1的強化學習階段,GRPO(Group Relative Policy Optimization)算法發(fā)揮了巨大的作用。GPRO算法的精髓在于它通過同一組回答的相對好壞來引導模型學習,就像 “拔河比賽”,不是看絕對力量,而是看在團隊中的相對貢獻。具體來說, GRPO通過組內樣本的相對比較直接計算優(yōu)勢函數,省去了傳統(tǒng)PPO算法中與策略模型同等規(guī)模的價值模型(Critic),顯存占用減少約50%,實現了更快的訓練速度。 此外基于組內相對表現的優(yōu)勢計算對獎勵尺度變化更具魯棒性,減少了模型通過“欺騙”獎勵函數獲得高分的行為。總的來看GRPO更高效。
4. 動態(tài)知識蒸餾(Knowledge Distillation)
知識蒸餾(Knowledge Distillation)是一種通過讓小模型從大模型中學習知識的技術。這項創(chuàng)新技術能夠將6600億參數的大型模型的能力“壓縮”到僅有1.5B參數的小模型中,猶如將超算能力“裝進”一臺筆記本電腦。
知識蒸餾的基本流程:
a. 大模型生成高質量數據
通過大模型(e.g.DeepSeek-R1)生成大量推理過程,包括數學計算、代碼推理等任務的詳細答案。這些答案不僅包含最終結果,還包括完整的推理鏈條,幫助小模型理解解題邏輯和推理過程。
b. 小模型學習大模型的輸出
小模型不會從零開始訓練,而是通過監(jiān)督微調(Supervised Fine-Tuning,SFT)來模仿大模型的推理過程。通過不斷優(yōu)化,小模型逐漸學會像大模型一樣進行高效的推理,最終實現與大模型相媲美的性能。