
2022-11-01 11:31:48
來源:淵亭科技
近年來,強化學習技術在游戲、技術科學領域取得了優異的表現,如 DeepMind 的 AlphaGo Zero 在圍棋比賽中擊敗人類頂尖圍棋高手、OpenAI Five 訓練的智能體在 Dota2 5v5中擊敗人類玩家等。但是,作為機器學習的重要分支之一,強化學習也同樣面臨著可解釋性不足的痛點,即在實際應用中“難以被理解”,也因此“難以被信任”,這導致了強化學習在對安全敏感的業務領域(比如醫療、自動駕駛等)發展受到了較大的限制。
DataExa-Nash 多智能體
淵亭科技推出的面向決策智能應用場景的「多智能體分布式學習框架DataExa-Nash」,是一個面向作戰指揮、無人系統集群協同、策略仿真等智能決策場景的高性能系統,為多智能體模型的設計、訓練、發布、對抗模擬和復盤分析等任務過程提供全生命周期支撐。
DataExa-Nash在集成多種SOTA多智能體算法(MAPPO、MADDPG、QMIX、RODE等)的基礎上,統一了深度強化學習算法開發范式和評估體系,簡化了開發進程,研究人員使用該框架可以大大降低多智能體開發的難度。
同時,DataExa-Nash提供了高效的分布式并行訓練能力,可用于創建并行性更強的智能體,特別適用于不完備信息、非穩態環境下的推理決策,比如策略游戲(星際爭霸等)、常規棋類(圍棋象棋等)、無人系統(無人機集群協同等)、機器人操作、作戰指揮(仿真推演等)等各種復雜決策場景。
DataExa-Nash中的可解釋性技術
強化學習過程中智能體(Agent)和環境(Environment)往復交互,智能體不斷從環境中學習和探索如何獲取最大獎勵值(Reward),逐步構建行為(Action)決策能力。DataExa-Nash圍繞強化學習核心要素-環境和智能體(任務的建模,被蘊含在平臺固化的能力和設計過程中),進行可解釋性特性的構建。具體如下圖所示:
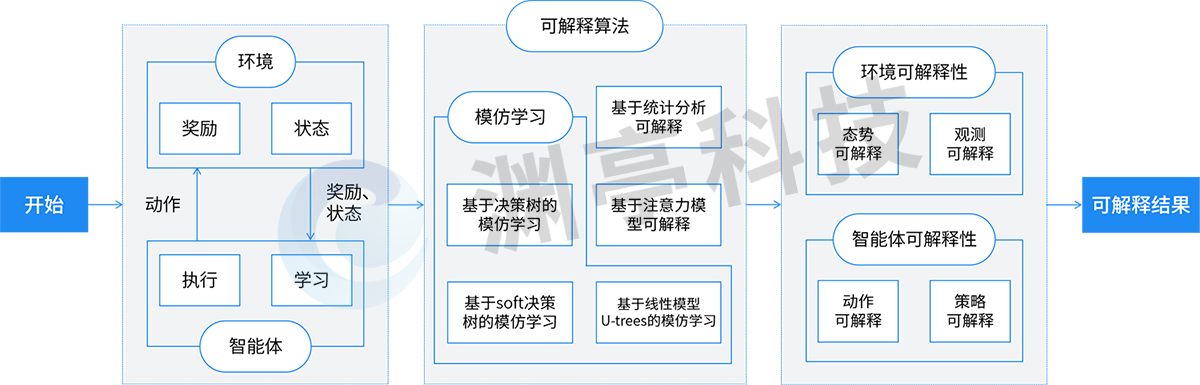
DataExa-Nash可解釋技術示意
DataExa-Nash可解釋技術示意展現了Nash和可解釋性相關的主要流程及采用技術,Nash基于諸多可解釋算法對智能體和環境交互過程進行拆解,形成環境可解釋性和智能體可解釋性。
1.DataExa-Nash可解釋性基礎
DataExa-Nash中集成了多種可解釋性算法,如基于決策樹的模仿學習、基于線性模型U-trees的模仿學習、基于Soft決策樹的模仿學習、基于注意力模型可解釋及基于統計分析可解釋等算法。DataExa-Nash集成了模仿學習類型的可解釋性算法,可以很好的利用已經具備可解釋性的算法對智能體行為進行解釋;集成了注意力類型的可解釋性算法,可以對環境中全局態勢和單個觀測態勢進行解釋;基于統計分析可解釋方法,可以對態勢、行為及獎勵等特征對智能體決策的影響進行分析,從而產生決策的可解釋性。
2.環境可解釋性
環境可解釋性是指對環境中態勢轉移的內部機理進行解釋。在強化學習中,環境是具備一定的黑盒性的。環境可解釋性的構建,有利于理解環境態勢變化對智能體決策可能的影響,更準確
3.智能體可解釋性
DataExa-Nash-可解釋性技術的應用案例
1.基于星際爭霸Ⅱ的可解釋技術應用
星際爭霸Ⅱ是由暴雪娛樂在2010年7月27日推出的一款即時戰略游戲,是《星際爭霸》系列的第二部作品。DataExa-Nash 基于注意力模型在星際爭霸Ⅱ地圖構建5個紅方智能體角色和7個電腦角色對戰的場景,通過分析環境中哪些態勢信息對智能體決策影響最大,即找到決策關鍵關聯因素,為智能體的決策提供解釋,具體效果如下圖所示。
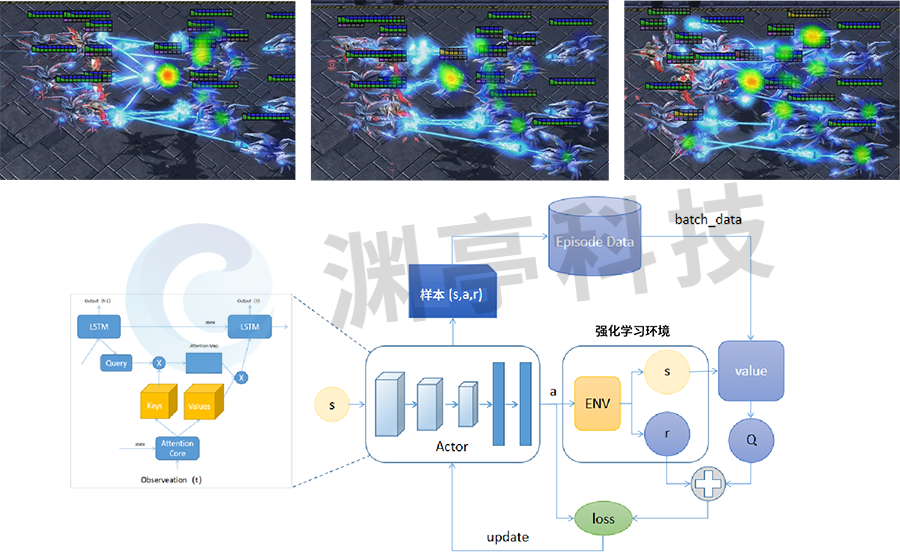
圖 1 基于注意力模型的星際爭霸Ⅱ可解釋性
DataExa-Nash 中基于注意力模型,觀測在星際爭霸Ⅱ智能體和電腦的對抗過程中敵方各個態勢對智能體決策的影響,判定敵方單元血量和敵方單元火力在決策過程中的影響最為明顯。從左側第一個圖至最后一個圖,展現了智能體根據觀測到的敵方態勢變化調整射擊動作決策的過程,由開始集中火力攻擊某個電腦角色,到隨著敵方該角色血量逐漸變少,射擊逐步集中到其它威脅較大的智能體上。
2.基于兵棋推演的可解釋技術應用
六角格地圖的兵棋推演仿真環境是一種典型的仿真環境,這類環境模擬了多種復雜的地理環境(如高程、居民地、叢林、道路等),并包含有豐富的兵棋算子(如重型坦克、中型戰車、無人戰車、炮兵等)。探索該模式下強化學習訓練智能體的決策可解釋性,非常具有典型性。DataExa-Nash 可以接入此類環境,使用基于注意力模型、基于數據等方式,進行可解釋性的探索,具體過程如下圖所示。

圖 2 基于注意力模型的兵棋智能體可解釋性
以上是一次典型的推演過程中,DataExa-Nash 利用注意力機制分析計算的關鍵決策節點,對節點的行為進行可解釋性的計算和輸出。該模式基于群隊想定下藍方智能體的視角進行訓練,智能體決策過程關注戰場態勢變化。其中圖(1)展現藍方未發現敵方且奪控點均未被奪控,藍方智能體的決策觀點基本為搶占主奪控點和次要奪控點,此時智能體主要動作合集(移動)都是為了到達奪控點然后進行奪控;圖(2)藍方智能體發現了紅方,此時智能體的關注點轉移到了紅方目標,智能體動作合集主要動作由之前的移動變為了攻擊;圖(3)藍方智能體發現主要奪控點被奪控,主奪控點關注度明顯變高。
除注意力機制之外,DataExa-Nash 也可以基于數據開展可解釋性分析(例如基于多局智能體推演決策數據統計結果進行分析,如下圖),實現深度強化學習模型的可解釋,直觀展示得到模型結果的關鍵信息。
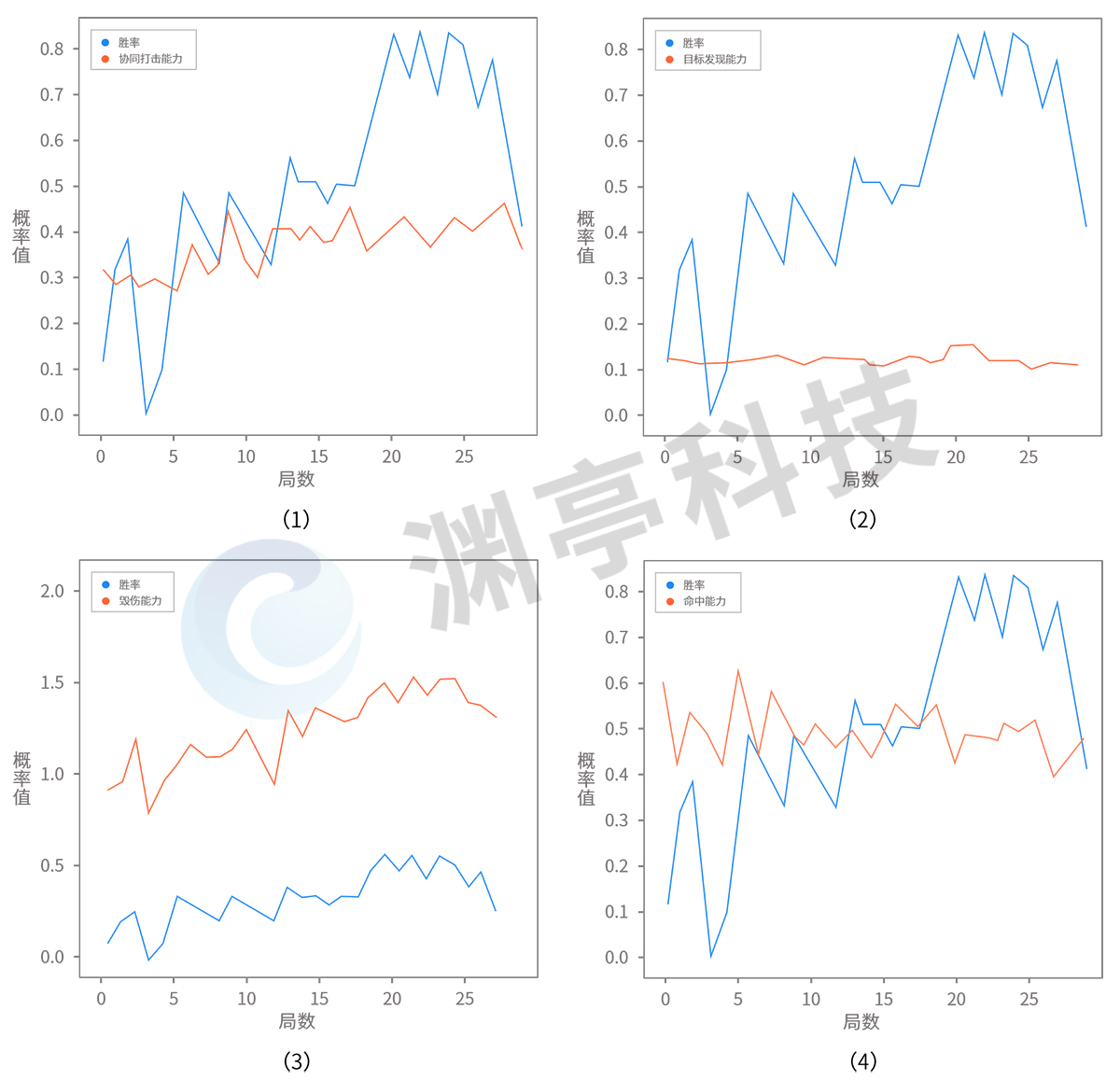
圖 3 基于數據的兵棋智能體可解釋性
以上展示了智能體不同能力(如協同打擊能力、毀傷能力、目標發現能力等)對最終勝率的影響。圖(1)是智能體協同打擊能力與勝率曲線變化;圖(2)是智能體的目標發現能力與勝率曲線變化;圖(3)是智能體的毀傷能力與勝率曲線變化;圖(4)是智能體命中能力與勝率曲線變化。可以明顯發現智能體的毀傷能力和協同打擊能力對最終勝率影響最大。
延伸閱讀:
關于強化學習缺乏可解釋性
強化學習缺乏可解釋性的主要表現如下:
(1)如同黑盒一般難以理解。對于普通用戶而言,經典強化學習在應用深度神經網絡(Deep Neural Networks,DNN)模型后,表現得愈發復雜,如同一個黑盒:給它一個態勢信息作為輸入,經過一定計算,反饋決策結果。無法確切地知道背后的決策依據以及做出的決策是否可靠。由于缺乏可解釋性,強化學習策略的可靠性經常受到挑戰,從而也給強化學習在實際場景應用中帶來非常大的阻礙。
(2)難以評估是否學到現實有用的知識。目前強化學習應用在仿真環境中具有優異表現,如 OpenAI Gym、星際爭霸II等,但仿真與真實世界往往存在一定的差異,很難做到完全與真實場景完全一致。而強化學習在仿真環境下開展大規模訓練時,難以避免對仿真環境的過擬合。當過擬合發生時,模型學到的知識是否在現實場景下同樣有效,沒有一套有效的評估手段和解釋。
(3)難以評估學到的知識對環境變化的適應性。強化學習的策略通常與環境存在強耦合。在仿真環境訓練過程中,經常出現只是對仿真環境參數做出較小修改,都會導致強化學習無法給出合理的決策。在實際應用中,也就難以確定強化學習訓練出來的模型是否具備較好泛化性,能夠適應環境的變化。
強化學習可解釋性(Explainable Reinforcement Learning,XRL)是人工智能可解釋性(Explainable Artificial Intelligence, XAI)的子問題。為了克服強化學習可解釋差的弱點,行業內開展了大量的相關研究。目前,強化學習可解釋技術的研究仍處于發展的初期階段,且很多技術直接繼承于人工智能可解釋性。
1.可解釋性概念
可解釋性是人與決策模型之間知識體系連接的橋梁,它既是決策模型的準確代理,也是人所可以理解的。具體說來,強化學習可解釋性技術,主要是幫助人理解模型是如何工作的,進而對模型結果的置信度建立概念:它從環境中學到了什么,是否學到了真正的知識,知識的應用是否具備一定魯棒性,針對每個態勢輸入它為什么會做出這樣的決策、以及它所做的決策是否可靠的。
2.可解釋性技術
可解釋性技術通常分為事前可解釋性(Ante-Hoc)和事后可解釋性(Post-Hoc)。其中事前可解釋性指通過訓練結構簡單、可解釋性好的模型或將可解釋性結合到具體的模型結構中的自解釋模型,從而讓模型本身具備一定可解釋能力。事后可解釋性又劃分為全局可解釋性和局部可解釋性,其中全局可解釋性是對模型的整體邏輯和內部工作機制進行解釋,局部可解釋性是針對模型決策過程和決策結果進行解釋。
3.強化學習可解釋方法
強化學習可解釋性方法有:基于視覺感官的解釋、基于模仿學習的解釋、基于分層強化學習的解釋等。
(1)基于視覺感官的解釋是通過對輸入態勢信息對動作的影響,對關鍵信息進行局部高亮顯示,從而讓人直觀上了解到模型決策的依據,常見的可解釋方法有基于注意力模型強化學習方法、基于擾動的顯著性方法等。
(2)基于模仿學習的解釋是利用具備較強解釋能力的模型對強化學習訓練的智能體進行行為的克隆學習,從而利用自身可解釋性對智能體的決策進行解釋,常見的可解釋方法有基于線性模型U樹的模仿學習、基于決策樹混合專家樹的模仿學習、基于軟決策樹模型的模仿學習等。
(3)基于分層強化學習的解釋是根據相近的動作是為了完成同一個目標的特點,將決策序列劃分為多個子任務,從而實現對模型從策略層面進行解釋,常見的可解釋方法有基于符號深度強化學習框架的解釋算法、基于點對點的可解釋的分層強化學習、基于獎勵分解的最小需求解釋算法等。



















