大國之間的復雜博弈使得當代戰爭復雜性急劇增加。在此背景下,2022年2月,美蘭德公司發布《模擬仿真和兵棋推演中的人工智能》報告,討論了人工智能(AI)如何應用于政治、軍事的模擬仿真和兵棋推演中;提出了三個主要觀點:模擬仿真和兵棋推演是相互關聯的研究方法,應該一起使用;AI可以對每一種方法做出貢獻;用于兵棋推演的AI應該由模擬仿真提供信息,而用于模擬仿真的AI應該由兵棋推演提供信息。
模擬仿真、兵棋推演的區別與聯系
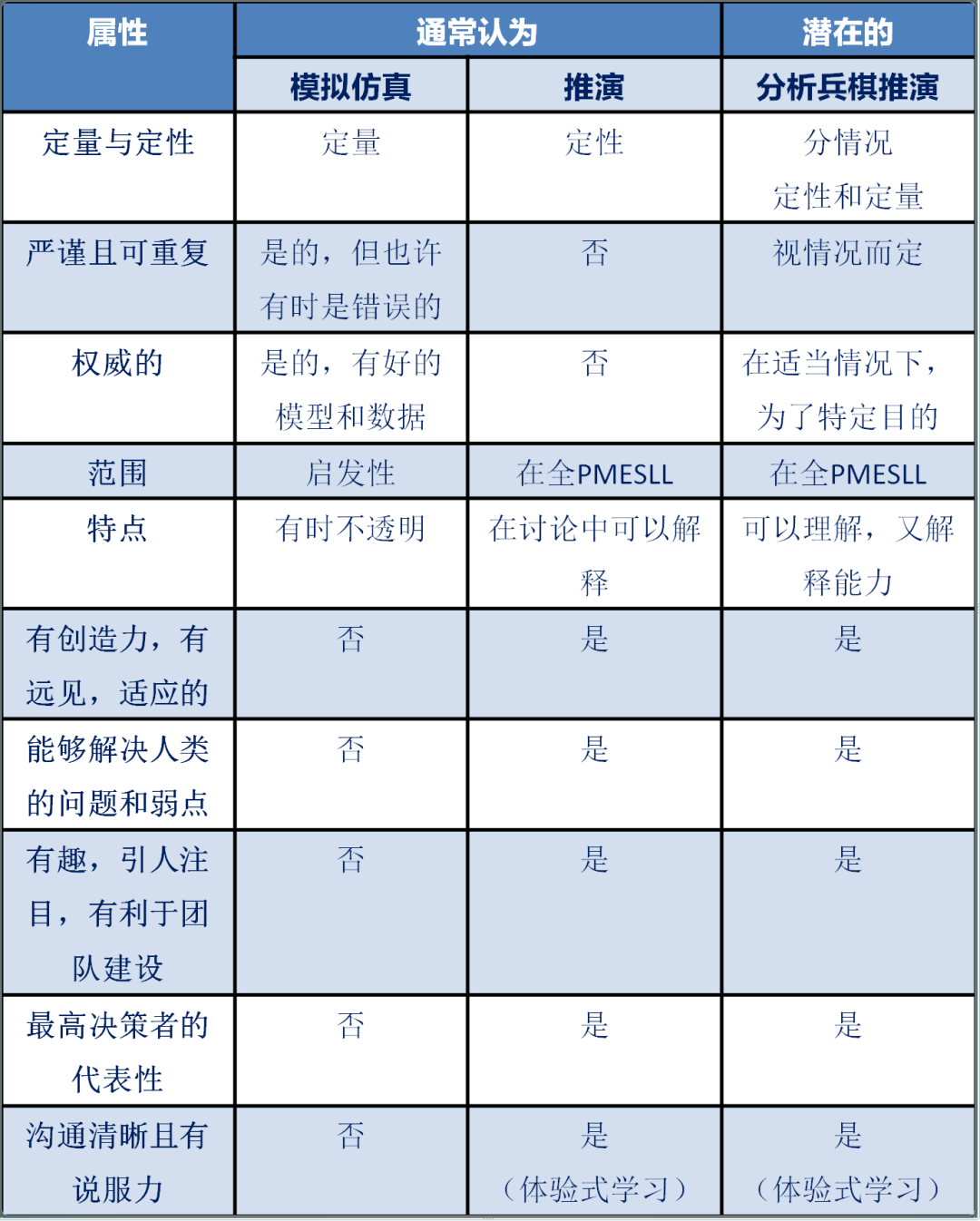
模擬仿真、兵棋推演有不同的優點和缺點,如表1所示。模擬仿真重在“定量”,但由于未能反映人的定性考慮而受到極大限制。有的批評者認為模擬仿真的“嚴謹”所產生的結果雖然是精確的,但卻可能是錯誤的,而兵棋推演則可以糾正這些缺點。
表1 模擬仿真和兵棋推演之間的差異
兵棋推演處于同樣受爭議的境地。一方面,兵棋推演的各方面成就使得模擬仿真受益匪淺;另一方面,兵棋推演的質量參差不齊,有的純粹是浪費時間,有的是與事實完全相反的結果,有的則能提供獨到、豐富的見解。
該報告認為,應該綜合運用兩種方法。如圖1所示,隨著時間的推移,從模擬仿真和兵棋推演中獲得的經驗被吸收借鑒,使用人工智能從模擬仿真實驗中挖掘數據(第4項),以便為后續的過程補充完善理論和數據(第5項)。在任何時候,根據問題定制的“模擬仿真-兵棋推演”模型可以解決現實世界的問題(第7項)。如同在淺灰色的氣泡中,人類團隊的決策輔助工具(項目6a)和主體(Agent)的啟發式規則(項目6b)被生成和更新。有些是直接構建的,但其他的是從分析模擬仿真實驗和兵棋推演中提煉出來的知識。該報告認為這個綜合模型與專注于一個或幾個單一模型形成鮮明對比,總體上來說是具有革命性意義的。
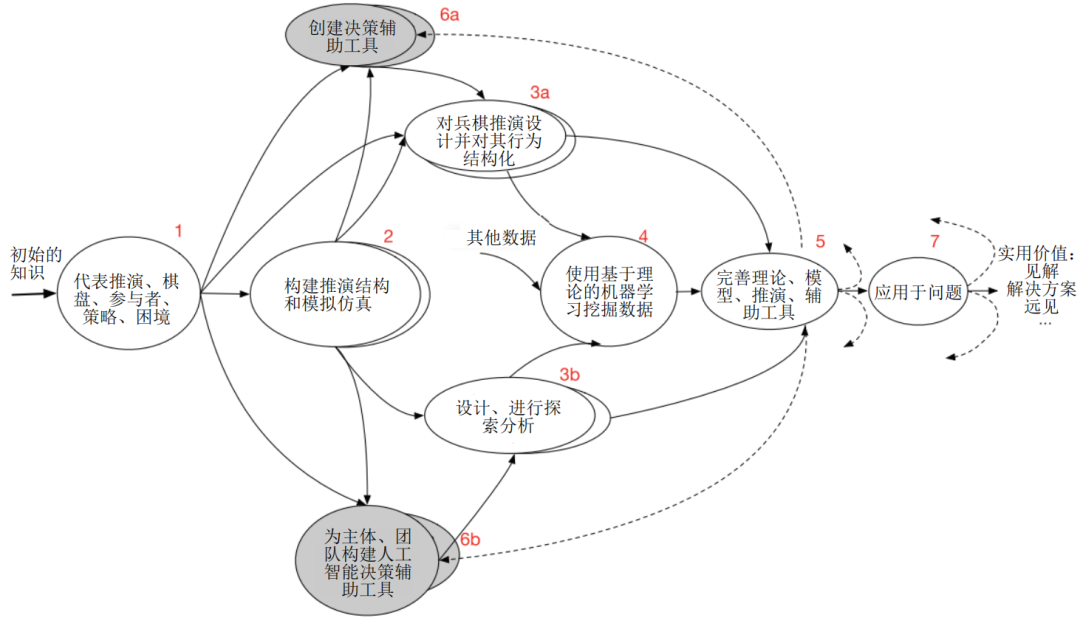
顯示了一個相應的愿景
大國之間復雜博弈帶來認知復雜性
該報告認為今天的國際安全挑戰遠遠超出了冷戰時期的挑戰,各國迫切需要新的兵棋推演和新的軍事戰略。
多極化和擴散。該報告認為世界現在有多個決策中心,它們的行動是相互依賴的。從概念上講,這將人類置于多體博弈論的世界中。但是由于各種原因,多體博弈論解決方案的概念沒有被廣泛采用。盡管目前在戰略穩定方面已經做了一些努力,但現實世界的多極化可能太復雜而導致無法建模。隨機混合策略通常在多體博弈中的作用很小。同樣,在計算其他參與者的行動時可能存在更多的內在復雜性,以至于隨機化產生的額外一層不確定性對我們理解未來的危機動態幾乎沒有幫助。
多維戰爭。相比1980年,現在擁有大規模殺傷性武器的國家更多。網絡作為一種戰略武器的加入使事情變得更加復雜。武器裝備的變化擴大了高端危機和沖突的維度,如遠程精確打擊和新形式的網絡戰、信息戰和太空戰。
有限高端戰爭的可行性。一個未被充分認識的推論是,世界現在比以前更適合有限的高端戰爭,在這種戰爭中——盡管更熱衷于威懾理論的人觀點相反——可能會有博弈中的贏家和輸家。曠日持久的“有限”戰略戰爭現在極有可能發生。
盟友之間相互沖突的目標。該報告認為,今天的美國盟友有著不同的重要利益和看法。北約在整個冷戰期間表現出的非凡的團結,在現代危機或沖突中可能無法重現。在亞太地區,相關國家之間的矛盾關系構成了危機中困難的預兆。所有這些國家都有通過使用太空、網絡空間或區域范圍內的精確武器進行升級的選擇。該報告認為,人類可能正在進入一個類似于20世紀初的多極化階段。
各類新興技術給建模問題帶來機遇
各類新興技術在各領域的廣泛應用,給國家安全相關的建模問題帶來了新的機遇。典型的新技術包括如下幾個。
基于主體的建模。基于主體的建模(ABM)已經取得了很大的進展,并且對于提供現象如何展開的因果理解的生成建模尤其重要。這種生成模型是現代科學的革命性發展。與早期專家系統的主體不同,今天的主體本質上是典型的目標尋求或位置改進,這可能使它們更具適應性。
模塊化和專門構建的模型組合。現在,構建獨立有用的模型(如模塊)并根據問題的需要組成更復雜的結構是有意義的。模塊化設計允許對正在建模的內容進行替換,這可以開闊思維,避免意外或為適應做準備。此外,模塊化開發有助于插入針對特定問題的專門化,這是建模師和分析師團體在2000年中期美國防部研討會上推薦的方法。
數據驅動的AI/機器學習。人工智能這個術語現在通常用來指機器學習(ML),它只是人工智能的一個版本。最大似然法已經有了很大的進步,最大似然法模型在擬合過去的數據和發現其他未被認識的關系時經常是準確的。
深度不確定性下的決策。在“深度不確定性下的決策”主題下,討論的規劃概念和技術已經發生了根本性的進展(DMDU)。在許多不確定的假設中,預期表現良好的策略。盡管在過去,不斷增加的不確定性常常令人麻痹,但今天卻不必如此。這些見解和方法在國防規劃和社會政策分析中有著悠久的歷史,應該被納入人工智能和決策輔助。
設計“永不停機”的智能系統。從技術上來說,大多數國防部的“模擬仿真-兵棋推演”模型被人工智能稱為“轉換”。模型或游戲有一個起點,它運行,然后報告贏家和輸家。可以進行多次運行并匯總結果,以捕捉復雜動力學中固有的變化。新的人工智能模型設計不同,模擬“永遠在線”的系統。這被稱為反應式編程,不同于轉換式編程。這些系統從未停止,也不只是將輸入數據轉換成輸出數據。
“AI+模擬仿真+兵棋推演”新模型
該報告為構建一個完整的“AI+模擬仿真+兵棋推演”架構給出了相關建議。圖2勾勒了一個頂層架構,在考慮許多可能的危機和沖突時,需要深入關注至少三個主要的行為者,以解決當前時代的危機和沖突。圖2還要求對軍事模擬采取模塊化方法。

多方博弈結構模擬
該報告認為,為大規模情景生成、探索性分析和不確定性下的決策做準備是必要的,需要強調兩個重要問題:第一,只有當模擬在結構上是有效的(即模型本身是有效的),不同參數值的探索性分析才是有用的;第二,從探索性分析中得出結論是有問題的,因為所研究的案例(方案)的可能性不一樣,它們的概率是相關的,但沒有分配概率分布的良好基礎。
模型的有效性和數據的有效性應該分別用于描述、解釋、后預測、探索和預測。參數化方法有很大的作用,但模型的不確定性經常被忽視,需要更多的關注。
結語
綜上所述,該報告認為模擬仿真和兵棋推演是相互關聯的研究方法。在“AI+模擬仿真+兵棋推演”模型中,用于兵棋推演的AI應該由模擬仿真提供信息,用于模擬仿真的AI應該由兵棋推演提供信息。需要指出的是,該模型仍將是不完美的,但卻有可能提高決策的質量。